









服務熱線
0755-83044319

發布時間:2024-06-07作者來源:薩科微瀏覽:1361

6月2日晚間,英偉達(NVIDIA)CEO黃仁勛在中國臺灣大學綜合體育館發表主題為“開啟產業革命的全新時代”的主題演講。在長達兩個小時的發言中,黃仁勛梳理并介紹了英偉達如何推動人工智能(AI)演進,以及AI如何變革工業。同時,他還宣布,Blackwell芯片現已開始投產,2025年將會推出Blackwell Ultra GPU芯片。下一代AI平臺名為“Rubin”,將集成HBM4內存,將于2026年發布。
過去十年,計算成本降低了100萬倍
計算機行業發展至今已有 60 年的歷史。從IBM System 360 引入了中央處理單元、通用計算、通過操作系統實現硬件和軟件的分離、多任務處理、IO子系統、DMA以及今天使用的各種技術。架構兼容性、向后兼容性、系列兼容性,所有今天對計算機了解的東西,大部分在1964 年就已經描述出來了。PC 革命使計算民主化,把它放在了每個人的手中和家中。
2007 年,iPhone 引入了移動計算,把計算機放進了我們的口袋。從那時起,一切都在連接并隨時運行通過移動云。這 60 年來,我們只見證了兩三次,確實不多,其實就兩三次,主要的技術變革,計算的兩三次構造轉變,而我們即將再次見證這一切的發生,即GPU(圖形處理器)所帶來的加速計算。

黃仁勛表示,計算機行業在中央處理器(CPU)上運行的引擎,其性能擴展速度已經大大降低。但我們必須做的計算量,仍然在以指數級的速度增長,如果所需的性能沒有如此增長,那么行業將經歷計算的通貨膨脹。和計算成本的提升。他指出,有一種更好的方法增強計算機的處理性能,減輕CPU的負擔,那便是通過專用處理器,來實現了對于密集型應用程序的加速。
“現在,隨著CPU擴展速度放緩,最終基本停止,我們應該加快讓每一個處理密集型應用程序都得到加速,每個數據中心也肯定會得到加速,加速計算是非常明智的,這是很普通的常識。”黃仁勛表示。
他指出,計算機圖形學是一門完全可以并行操作的學科。計算機圖形學、圖像處理、物理模擬、組合優化、圖形處理、數據庫處理,以及深度學習中非常[敏感詞]的線性代數,許多類型的算法都非常適合通過并行處理來加速。

“通過結合GPU和CPU可以加速計算。我們可以讓計算速度加快100倍,但功耗只增加了大約三倍,成本只增加了約 50%。”黃仁勛表示,英偉達在 PC 行業一直這樣做,比如在1000 美元 PC 上加一個 500 美元 GeForce GPU,性能會大幅提升。在數據中心領域,英偉達也是這樣做的,10億美元的數據中心增加了5億美元的GPU,它一下子變成了AI工廠。通過加速運算,還可以節省成本和能源。

黃仁勛指出,每一次加快應用程序的速度,計算成本就會下降,速度上升100倍,就可以節省96%、97%、98%的成本。在過去十年間,一種特定算法的邊際計算成本降低了100萬倍。“現在我們得以用互聯網上所有數據來訓練大語言模型。人工智能出現成為可能,是因為我們相信隨著計算變得越來越便宜,將會有人找到很好的用途。”
英偉達推動了大語言模型的誕生
黃仁勛強調,加速計算確實帶來了非凡的成果,但它并不容易。原因是因為這非常難。沒有一種軟件可以通過C編譯器運行,突然間應用程序就快了100倍。這甚至不合邏輯。如果可以做到這一點,他們早就改造 CPU了。因此,對于英偉達來說,必須重寫軟件,這是最難的部分。軟件必須完全重寫,以便能夠重新表達在 CPU 上編寫的算法,使其能夠被加速、卸載并行運行。這種計算機科學的改變極其困難。
為了推動GPU所能夠帶來的計算加速,英偉達在2012年后改變了GPU的架構,采用Tensor Core(張量計算單元),并推出了一種協助“CPU任務分發+GPU并行處理”的編程模型/平臺——CUDA,用于加速GPU和CPU之間的計算。 可以說,CUDA 增強了 CPU,卸載并加速了專用處理器可以更好完成的工作。
隨后,黃仁勛花了較大篇幅來強調英偉達運算平臺CUDA的重要性。黃仁勛表示,作為使用神經網絡來進行深度學習的平臺,CUDA顯著推動了計算機科學在近20年內的進展。現在,全球已有500萬名CUDA開發者。
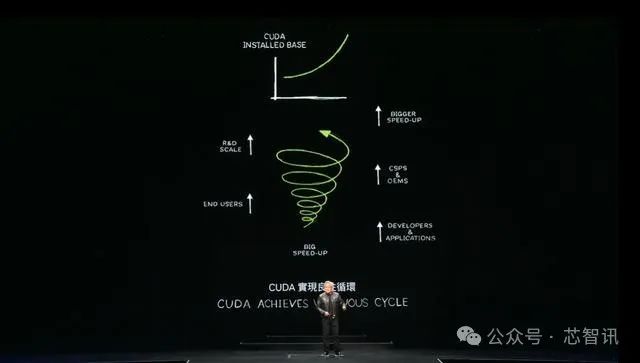
黃仁勛指出,CUDA已經實現了“良性循環”,能夠在運算基礎不斷增長的情況下,擴大生態系統,令成本不斷下降:“這將促使更多的開發人員提出更多的想法,帶來更多的需求實驗,成為偉大事業的開端。”
在CUDA之后,英偉達還發明了NVLink(一種總線及其通信協議),然后是TensorRT、NCCL,收購了Mellanox,推出TensorRT-ML、Triton推理服務器,所有這些都整合在一臺全新的計算機上,助力了生成式AI的誕生。
“當時沒人理解這件事(推出CUDA,并使得英偉達GPU支持CUDA),我也不認為會有人來買,當時我們在GTC大會上宣布了這件事,舊金山的一家小公司OpenAI看到了,他們便要我給他們送去一臺。”黃仁勛表示,2016年,英偉達向OpenAI交付了[敏感詞]臺DGX超級計算機,隨后繼續擴展超級計算機的能力,以便訓練大量數據。2022年11月,基于成千上萬的英偉達GPU加速卡,OpenAI推出了ChatGPT,并在5天內收獲了上百萬名用戶。
加速新的工業革命
Blackwell已投產,2026年推出Rubin GPU
在今年3月的GTC2024大會,英偉達正式發布了面向下一代數據中心和人工智能應用的Blackwell GPU,時隔僅不到3個月,在此次的臺大演講當中,黃仁勛就披露了下一代的Blackwell Ultra GPU和再下一代的Rubin GPU。

據介紹,目前Blackwell芯片已經開始投產,它是當今世界上最復雜、性能[敏感詞]的計算芯片。相比八年前的Pascal芯片,Blackwell芯片的AI算力提升了1000倍。

黃仁勛表示,英偉達在8年時間里,計算能力、浮點運算以及人工智能浮點運算能力增長了1000倍。這樣的增長速度,幾乎超越了摩爾定律在[敏感詞]時期的增長。
此外,相比八年前的Pascal芯片,Blackwell芯片用于訓練GPT-4模型(2萬億參數和8萬億Token)訓練的能耗下降了350倍。
黃仁勛解釋稱,如果使用Pascal進行同樣的(GPT-4模型)訓練,它將消耗高達1000吉瓦時的能量。這意味著需要一個吉瓦數據中心來支持,但世界上并不存在這樣的數據中心。即便存在,它也需要連續運行一個月的時間。而如果是一個100兆瓦的數據中心,那么訓練時間將長達一年。然而,利用Blackwell進行訓練,則可以將原本需要高達1000吉瓦時的能量降低到僅需3吉瓦時,這一成就無疑是令人震驚的突破。想象一下,使用1000個GPU,它們所消耗的能量竟然只相當于一杯咖啡的熱量。而10,000個GPU,更是只需短短10天左右的時間就能完成同等任務。
Blackwell不僅適用于推理,其在Token生成性能上的提升更是令人矚目。在Pascal時代,生成每個Token消耗的能量高達17,000焦耳,這大約相當于兩個燈泡運行兩天的能量。而生成一個GPT-4的Token,幾乎需要兩個200瓦特的燈泡持續運行兩天。考慮到生成一個單詞大約需要3個Token,這確實是一個巨大的能量消耗。
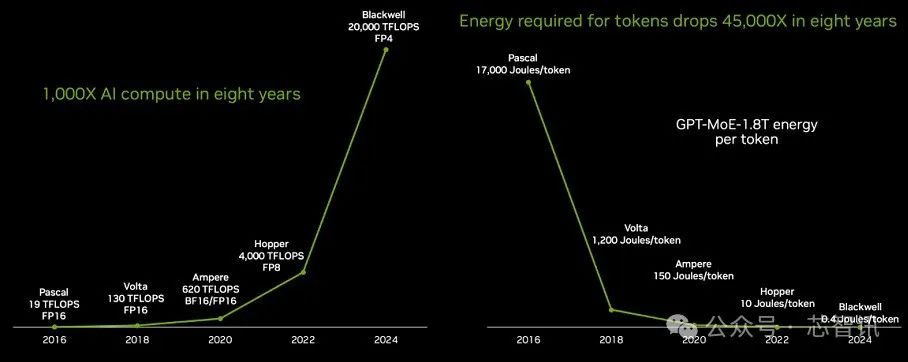
現在的情況已經截然不同,Blackwell的推出使得生成每個Token只需消耗0.4焦耳的能量,以驚人的速度和極低的能耗進行Token生成。相比Pascal的Token生成能耗降低了約350倍,這無疑是一個巨大的飛躍。

但即使如此,英偉達仍不滿足,為了更大的突破,在推出整合Blackwell芯片的DGX系統的同時,英偉達還在持續研發新一代的GPU。
黃仁勛透露,英偉達將會在2025年推出增強版的Blackwell Ultra GPU(8S HBM3e 12H)。在2026年,英偉達還將推出再下一代的Rubin GPU,將集成8顆HBM4,隨后在2027年,將推出Rubin Ultra GPU,將集成12顆HBM4版本。

根據外媒wccftech介紹,Rubin GPU將采用4x光罩設計,并將使用臺積電3nm制程,以及CoWoS-L封裝技術。
“在此展示的所有的新的芯片都處于全面開發階段,確保每一個細節都經過精心打磨。我們的更新節奏依然是一年一次,始終追求技術的[敏感詞],同時確保所有產品都保持100%的架構兼容性。”黃仁勛說道。
生成式AI加速以太網
但對于新的基于AI的工業革命來說,光有AI算力的提升這還不足以滿足需求,特別是對于大型人工智能工廠來說更是如此,因此還必須使用高速網絡將這些人工智能工廠連接起來。
對此,英偉達推出了兩種網絡選擇:InfiniBand和以太網。其中,InfiniBand已經在全球各地的超級計算和人工智能工廠中廣泛使用,并且增長迅速。然而,并非每個數據中心都能直接使用InfiniBand,因為很多企業在以太網生態系統上進行了大量投資,而且管理InfiniBand交換機和網絡確實需要一定的專業知識和技術。
因此,英偉達的解決方案是將InfiniBand的性能帶到以太網架構中,這并非易事。原因在于,每個節點、每臺計算機通常與互聯網上的不同用戶相連,但大多數通信實際上發生在數據中心內部,即數據中心與互聯網另一端用戶之間的數據傳輸。然而,在人工智能工廠的深度學習場景下,GPU并不是與互聯網上的用戶進行通信,而是彼此之間進行頻繁的、密集的數據交換。
它們相互通信是因為它們都在收集部分結果。然后它們必須將這些部分結果進行規約(reduce)并重新分配(redistribute)。
這種通信模式的特點是高度突發性的流量。重要的不是平均吞吐量,而是最后一個到達的數據,因為如果你正在從所有人那里收集部分結果,并且我試圖接收你所有的部分結果,如果最后一個數據包晚到了,那么整個操作就會延遲。對于人工智能工廠而言,延遲是一個至關重要的問題。
所以,英偉達關注的焦點并非平均吞吐量,而是確保最后一個數據包能夠準時、無誤地抵達。然而,傳統的以太網并未針對這種高度同步化、低延遲的需求進行優化。為了滿足這一需求,我們創造性地設計了一個端到端的架構,使NIC(網絡接口卡)和交換機能夠通信。
為了實現這一目標,英偉達采用了四種關鍵技術:
[敏感詞],英偉達擁有業界領先的RDMA(遠程直接內存訪問)技術。現在,我們有了以太網網絡級別的RDMA,它的表現非常出色;
第二,引入了擁塞控制機制。交換機具備實時遙測功能,能夠迅速識別并響應網絡中的擁塞情況。當GPU或NIC發送的數據量過大時,交換機會立即發出信號,告知它們減緩發送速率,從而有效避免網絡熱點的產生。
第三,采用了自適應路由技術。傳統以太網按固定順序傳輸數據,但在英偉達的架構中,其能夠根據實時網絡狀況進行靈活調整。當發現擁塞或某些端口空閑時,可以將數據包發送到這些空閑端口,再由另一端的Bluefield設備重新排序,確保數據按正確順序返回。這種自適應路由技術極大地提高了網絡的靈活性和效率。
第四,實施了噪聲隔離技術。在數據中心中,多個模型同時訓練產生的噪聲和流量可能會相互干擾,并導致抖動。英偉達的噪聲隔離技術能夠有效地隔離這些噪聲,確保關鍵數據包的傳輸不受影響。
通過采用這些技術,英偉達成功地為人工智能工廠提供了高性能、低延遲的網絡解決方案。在價值高達數十億美元的數據中心中,如果網絡利用率提升40%而訓練時間縮短20%,這實際上意味著價值50億美元的數據中心在性能上等同于一個60億美元的數據中心,揭示了網絡性能對整體成本效益的顯著影響。
幸運的是,帶有Spectrum X的以太網技術正是英偉達實現這一目標的關鍵,它大大提高了網絡性能,使得網絡成本相對于整個數據中心而言幾乎可以忽略不計。這無疑是英偉達在網絡技術領域取得的一大成就。
目前英偉達已經擁有一系列強大的以太網產品線,其中最引人注目的是Spectrum X800。這款設備以每秒51.2 TB的速度和256路徑(radix)的支持能力,為成千上萬的GPU提供了高效的網絡連接。接下來,我們計劃一年后推出X800 Ultra,它將支持高達512路徑的512 radix,進一步提升了網絡容量和性能。而X 1600則是為更大規模的數據中心設計的,能夠滿足數百萬個GPU的通信需求。

黃仁勛強調,隨著技術的不斷進步,數百萬個GPU的數據中心時代已經指日可待。這一趨勢的背后有著深刻的原因。一方面,我們渴望訓練更大、更復雜的模型;但更重要的是,未來的互聯網和計算機交互將越來越多地依賴于云端的生成式人工智能。這些人工智能將與我們一起工作、互動,生成視頻、圖像、文本甚至數字人。因此,我們與計算機的每一次交互幾乎都離不開生成式人工智能的參與。并且總是有一個生成式人工智能與之相連,其中一些在本地運行,一些在你的設備上運行,很多可能在云端運行。這些生成式人工智能不僅具備強大的推理能力,還能對答案進行迭代優化,以提高答案的質量。這意味著我們未來將產生海量的數據生成需求。
英偉達還宣布,包括華碩、技嘉、鴻佰科技、英業達、和碩、云達科技、美超威、緯創及緯穎、永擎電子等將利用英偉達的GPU與網絡技術,推出云端、本地端、嵌入式與邊緣AI系統。
AI機器人時代已經到來
展望未來,機器人技術將不再是一個遙不可及的概念,而是日益融入我們的日常生活。當提及機器人技術時,人們往往會聯想到人形機器人,但實際上,它的應用遠不止于此。機械化將成為常態,工廠將全面實現自動化,機器人將協同工作,制造出一系列機械化產品。它們之間的互動將更加密切,共同創造出一個高度自動化的生產環境。
未來,工廠內的機器人將成為主流,它們將制造所有的產品,其中兩個高產量機器人產品尤為引人注目:一個是自動駕駛汽車或具備高度自主能力的汽車;另一個則可能是由機器人工廠高產量制造的產品是人形機器人。

在自動駕駛汽車方面,英偉達宣布,明年計劃計劃與梅賽德斯-奔馳車隊攜手,隨后在2026年與捷豹路虎(JLR)車隊合作。英偉達提供完整的解決方案堆棧,但客戶可根據需求選擇其中的任何部分或層級,因為整個驅動堆棧都是開放和靈活的。
在人形機器人方面,黃仁勛表示,“近年來,在認知能力和世界理解能力方面取得了巨大突破,這一領域的發展前景令人期待。我對人形機器人特別興奮,因為它們最有可能適應我們為人類所構建的世界。與其他類型的機器人相比,訓練人形機器人需要大量的數據。由于我們擁有相似的體型,通過演示和視頻能力提供的大量訓練數據將極具價值。因此,我們預計這一領域將取得顯著的進步。”
黃仁勛還提出“數字人類”(digital humans)的概念,稱“數字人類是我們的愿景”,可應用在客服、廣告及電玩游戲等產業。
將加碼AI PC市場?
在演講中,黃仁勛還披露了英偉達進軍AI PC的企圖心。黃仁勛強調,英偉達在每一個 RTX GPU 中安裝了張量核心處理器,因此也可以理解為,現在全球有 1 億臺基于 GeForce RTX 的AI PC,有超過200款搭載英偉達芯片的RTX AI PC,包括華碩、微星等PC品牌廠商都是合作伙伴。

在本次 Computex 2024展會上,英偉達將展示四款新的令人驚嘆的筆記本電腦。黃仁勛表示,“它們都能夠運行AI,運行由AI增強的應用程序。未來的PC 將成為一個AI,它將不斷在后臺幫助你、協助你。你所有的照片編輯、寫作工具、你使用的一切工具都將由AI增強。你的PC還將托管帶有數字人類的 AI 應用程序。因此,AI 將在不同的方式中表現出來并被用于PC中。PC 將成為非常重要的 AI 平臺。”
值得注意的是,近期業內有傳言稱,英偉達(Nvidia)正準備推出一款將下一代 Arm Cortex CPU內核與其 Blackwell GPU內核相結合的芯片,主要面向Windows on Arm的AI PC設備領域。
考慮到目前英偉達在云端人工智能領域的統治地位,在生成式AI開始從云端進入到邊緣端的趨勢之下,英偉達希望憑借其強大的GPU能力以及近年來在自研Grace Arm CPU上積累的經驗,以及期與PC制造商和服務器廠商多年來的深度合作,進入Arm Windows PC市場無疑一個市場機遇,特別是在PC市場正面臨生成式AI PC所帶來的換機潮的背景之下。
免責聲明:本文采摘自“芯智訊”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2024 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號
