









服務(wù)熱線
0755-83044319

發(fā)布時(shí)間:2022-10-25作者來(lái)源:芯智訊瀏覽:2143
攪翻計(jì)算生物界的AlphaFold2一開(kāi)源,各種加速方案就爭(zhēng)相涌現(xiàn)。
妹想到啊,現(xiàn)在居然有了個(gè)CPU的推理優(yōu)化版本,不用GPU,效果也出人意料的好——
端到端的通量足足提升到原來(lái)的23.11倍。
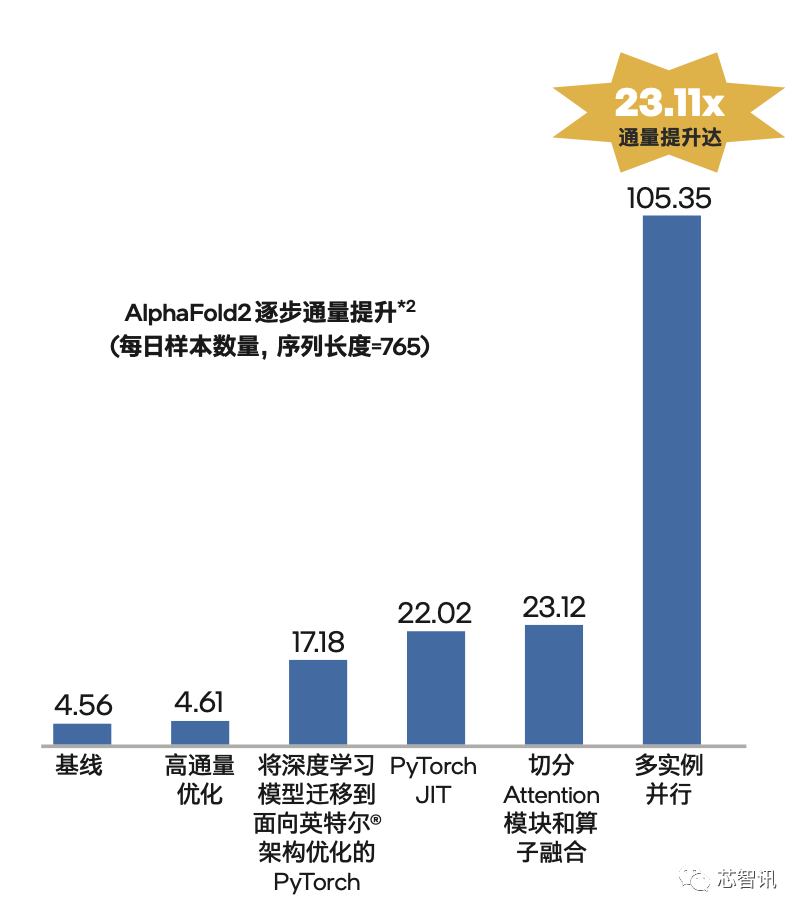
換個(gè)更具體的數(shù)據(jù),它直接讓AlphaFold2的通量從每天約4.6個(gè)序列提升到了約105.4個(gè)。
要知道,由DeepMind開(kāi)源的AlphaFold2,通過(guò)AI算法對(duì)蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)實(shí)現(xiàn)了接近實(shí)驗(yàn)精度的精準(zhǔn)預(yù)測(cè),可謂是公認(rèn)的AI for Science標(biāo)桿。
該領(lǐng)域也一直被認(rèn)為是最吃AI專(zhuān)用加速芯片,如GPU紅利的前沿方向。
這一[敏感詞]成果的釋出,就意味著CPU也能在AI for Science領(lǐng)域占有一席之地,并發(fā)揮巨大、而且是出乎大家意料的威力。
同樣,這個(gè)成果也意味著AI for Science的入場(chǎng)門(mén)檻正在被拉低,對(duì)那些想從事基礎(chǔ)科研和創(chuàng)新,但還沒(méi)有布局異構(gòu)IT基礎(chǔ)設(shè)施,或沒(méi)有大規(guī)模采用AI專(zhuān)用加速芯片的企業(yè)和機(jī)構(gòu)而言也是個(gè)難得的福音,意味著他們依靠更常見(jiàn)的IT基礎(chǔ)設(shè)施就能開(kāi)展工作。
那么這個(gè)優(yōu)化方案究竟是如何做到的?一起來(lái)看。
這在其預(yù)處理、推理、后處理三個(gè)部分都有所體現(xiàn)。
預(yù)處理階段,由于輸入的氨基酸序列所含信息不多,AlphaFold2一般會(huì)先利用已知信息(蛋白質(zhì)序列、結(jié)構(gòu)模板)來(lái)提升預(yù)測(cè)精度,以此拿到MSA表征(MSA representation)和鄰接表征(pair representation)的三維張量。
這就意味著AlphaFold2屬于大張量模型,在嵌入層的瓶頸不在于并行計(jì)算,而是在于內(nèi)存消耗和異構(gòu)數(shù)據(jù)通信。
這正是CPU所擅長(zhǎng)的領(lǐng)域。
再看模型推理階段。
該階段通過(guò)一個(gè)由48個(gè)塊(Block)組成的Evoformer網(wǎng)絡(luò)進(jìn)行表征融合。
該網(wǎng)絡(luò)的機(jī)制是利用Self-Attention來(lái)學(xué)習(xí)蛋白質(zhì)的三角幾何約束信息,讓兩種表征信息相互影響,從而使得模型能直接推理出相應(yīng)的三維結(jié)構(gòu),且要循環(huán)三次。
結(jié)構(gòu)層還會(huì)基于不動(dòng)點(diǎn)注意力機(jī)制,對(duì)三維結(jié)構(gòu)的每個(gè)原子進(jìn)行預(yù)測(cè),最后合成一個(gè)高度準(zhǔn)確的結(jié)果。
這一番動(dòng)作下來(lái),對(duì)算力是個(gè)大考驗(yàn)。
而且原版AlphaFold2會(huì)受到顯存限制,導(dǎo)致能夠探索的蛋白質(zhì)序列長(zhǎng)度不足1000aa。但很多蛋白質(zhì)的序列長(zhǎng)度動(dòng)輒都是2k、3k。
最終在后處理階段,將使用Amber力場(chǎng)分析方法對(duì)獲得的三維結(jié)構(gòu)參數(shù)優(yōu)化,并輸出最終的蛋白質(zhì)三維結(jié)構(gòu)。
DeepMind團(tuán)隊(duì)提到,他們用128塊TPUv3從頭訓(xùn)練一遍AlphaFold2,需要11天的時(shí)間。
同時(shí),AlphaFold2代碼是基于JAX的,偏向于專(zhuān)業(yè)從事AI科學(xué)計(jì)算的研究人員,普通開(kāi)發(fā)人員部署起來(lái)也比較困難。
種種挑戰(zhàn)之下,導(dǎo)致AlphaFold2自開(kāi)源后,相應(yīng)的加速方案也接連涌現(xiàn)。不過(guò)無(wú)論是訓(xùn)練還是推理,市面上更多見(jiàn)的,還是基于AI專(zhuān)用加速芯片,如GPU的方案。
完全基于CPU的加速方案還是頭一回見(jiàn),而且一上來(lái)就在性能增幅上震驚四座,推理通量可提升到優(yōu)化前的23倍之多。
具體到底是怎么做的?
提到CPU,你可能已經(jīng)想到方案的提出者是誰(shuí)了——
沒(méi)錯(cuò),就是那個(gè)名字,英特爾。
他們基于目前[敏感詞]的第三代至強(qiáng)可擴(kuò)展平臺(tái),最終實(shí)現(xiàn)了“23.11倍”的通量?jī)?yōu)化成果(相比未優(yōu)化時(shí)),其中有5.05倍是靠模型本身的優(yōu)化所帶來(lái),還有4.56倍則是來(lái)自傲騰持久內(nèi)存提供的TB級(jí)內(nèi)存支持。

其整體流程,就是先在預(yù)處理階段對(duì)模型進(jìn)行高通量?jī)?yōu)化,然后將模型遷移到PyTorch框架下,接著再在PyTorch版本上進(jìn)行細(xì)節(jié)上的推理優(yōu)化,最后給予TB級(jí)內(nèi)存支持以解決AlphaFold2的內(nèi)存瓶頸,由此達(dá)到不輸專(zhuān)用加速芯片的效果。
更具體點(diǎn),這些優(yōu)化一共分為五步。
如前文所述,此階段模型在進(jìn)行蛋白質(zhì)序列和模版搜索時(shí)需要計(jì)算平臺(tái)執(zhí)行大量的向量/矩陣運(yùn)算——處理器能不能夠火力全開(kāi)就顯得尤為重要。
[敏感詞]步優(yōu)化就在此展開(kāi),不過(guò)這步的優(yōu)化非常簡(jiǎn)單,就是借助至強(qiáng)可擴(kuò)展處理器自帶的多核心、多線程和大容量高速緩存能力直接加速,提升MSA和模板搜索通量。
至強(qiáng)可擴(kuò)展處理器內(nèi)置的AVX-512指令集和支持的NUMA ( Non-Uniform Memory Access,非一致存儲(chǔ)訪問(wèn)) 架構(gòu)等技術(shù),能以提供[敏感詞]512位向量計(jì)算能力的顯著高位寬優(yōu)勢(shì),來(lái)提升計(jì)算過(guò)程中的向量化并行程度,從而進(jìn)一步提升預(yù)處理階段的整體效率。
這步優(yōu)化支持所有至強(qiáng)可擴(kuò)展系列CPU,且只需在ICC編譯器中添加一句簡(jiǎn)單的配置就OK:
-O3 -no-prec-div -march=icelake-server
在預(yù)處理階段的高通量?jī)?yōu)化完成后,就需要將模型遷至PyTorch了。
因?yàn)樵糀lphaFold2所基于的JAX庫(kù)所提供的加速能力主要針對(duì)GPU,且在英特爾? 架構(gòu)平臺(tái)上能夠發(fā)揮的功能有限。
而PyTorch擁有良好的動(dòng)態(tài)圖糾錯(cuò)方法,與haiku-API有著相似的風(fēng)格(AlphaFold2一部分也基于haiku-API實(shí)現(xiàn)),就更別說(shuō)還有英特爾? oneAPI工具套件提供的針對(duì)PyTorch的優(yōu)化“利器”:Intel? Extensions for PyTorch (IPEX)。
因此,為了實(shí)現(xiàn)更好的優(yōu)化效果,需要在這里完成 PyTorch版本的遷移。
接下來(lái),為了提高模型的推理速度,便于后續(xù)利用IPEX的算子融合等加速手段進(jìn)行深入優(yōu)化,英特爾又將遷移后的代碼進(jìn)行了一系列的API改造,在不改變網(wǎng)絡(luò)拓?fù)涞那疤嵯拢隤yTorch Just-In-Time (JIT) 圖編譯技術(shù),將網(wǎng)絡(luò)最終轉(zhuǎn)化為靜態(tài)圖。
以上都還只是“熱身動(dòng)作”,下面才是展現(xiàn)“真正的實(shí)力”的時(shí)候——
首先,通過(guò)算法設(shè)計(jì)分析,英特爾發(fā)現(xiàn),在AlphaFold2模型的嵌入層有一個(gè)叫做ExtraMsaStack的模塊,其注意力模塊包含了大量的偏移量計(jì)算。
這些運(yùn)算需要靠張量間的矩陣運(yùn)算來(lái)完成。
其過(guò)程就會(huì)伴隨著張量的擴(kuò)張,而張量擴(kuò)張到一定規(guī)模后,就會(huì)讓模型內(nèi)存需求變得巨大。
比如一個(gè)“5120x1x1x64”的張量,其初始內(nèi)存需求只要1.25MB,擴(kuò)張過(guò)程中就可達(dá)到930MB。
這一下子爆出的內(nèi)存峰值壓力,會(huì)讓內(nèi)存資源在短時(shí)間耗盡,繼而可能引發(fā)推理任務(wù)的失敗。
同時(shí)別忘了,大張量運(yùn)算所需的海量?jī)?nèi)存還會(huì)帶來(lái)不可忽略的內(nèi)存分配過(guò)程,徒增執(zhí)行耗時(shí)。
那么,英特爾的第四步優(yōu)化就瞄準(zhǔn)這兩個(gè)“痛點(diǎn)”,對(duì)注意力模塊來(lái)了個(gè)“大張量切分”的優(yōu)化思路,化大張量為多個(gè)小張量。
比如將上述“5120x1x1x64”的張量切分為“320x1x1x64”后,其擴(kuò)張所需的內(nèi)存就由930MB降至59.69MB,只占原來(lái)的6.4%左右。
沒(méi)有了大內(nèi)存之需,也就不需要進(jìn)行內(nèi)存分配了,因此,張量切分后推理速度也上來(lái)了。
比如從下圖我們就可以看到,注意力模塊的效率在切片前后有著非常明顯的差別。

這還沒(méi)完。
接著,英特爾利用PyTorch自帶的Profiler對(duì)AlphaFold2的Evoformer網(wǎng)絡(luò)進(jìn)行了算子跟蹤分析。
然后他們發(fā)現(xiàn),有兩種算子(Einsum和Add)的資源占用率很高,且總是連續(xù)同時(shí)存在。
因此,英特爾就使用IPEX工具提供的算子融合能力將它倆的計(jì)算過(guò)程進(jìn)行融合,以省去中間建立臨時(shí)緩存數(shù)據(jù)結(jié)構(gòu)的時(shí)間,提高整體效率。
從下圖我們可以看到,兩算子融合后光是在單元檢測(cè)中的計(jì)算效率就提升到了原來(lái)的6倍。
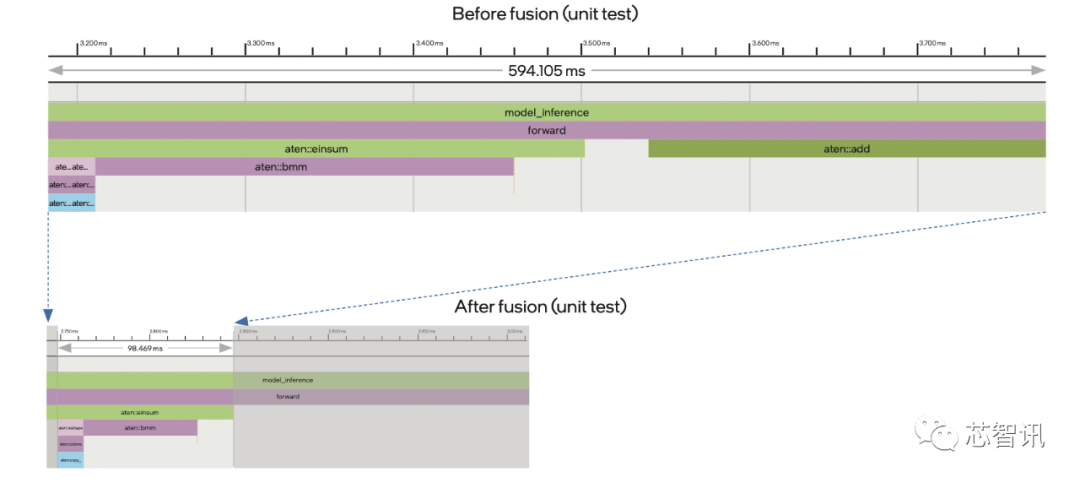
至此,經(jīng)過(guò)以上幾個(gè)步驟的優(yōu)化,AlphaFold2在CPU上的總體性能已經(jīng)得到了大約5倍的提升。
還差最后一步:
在這一步,英特爾先利用至強(qiáng)可擴(kuò)展平臺(tái)上基于NUMA架構(gòu)的核心綁定技術(shù),讓每個(gè)推理工作負(fù)載都能穩(wěn)定地在同一組核心上執(zhí)行,并優(yōu)先訪問(wèn)對(duì)應(yīng)的近端內(nèi)存,從而提供更優(yōu)、也更穩(wěn)定的并行算力輸出。
然后引入英特爾? MPI庫(kù)幫助模型在多實(shí)例并行推理計(jì)算時(shí)實(shí)現(xiàn)更優(yōu)的時(shí)延、帶寬和可擴(kuò)展性。
但這些動(dòng)作還不足以破解限制AlphaFold2發(fā)揮潛能的一個(gè)重要因素:內(nèi)存瓶頸。
眾所周知,在面向不同蛋白質(zhì)的結(jié)構(gòu)測(cè)序工作中,序列長(zhǎng)度越長(zhǎng),推理計(jì)算復(fù)雜度就越大。
而在我們對(duì)模型進(jìn)行了并行計(jì)算能力的優(yōu)化后,更多計(jì)算實(shí)例的加入還會(huì)進(jìn)一步凸顯這一問(wèn)題。
英特爾用“星際探索”這一比喻對(duì)這種現(xiàn)象做了非常形象的說(shuō)明。
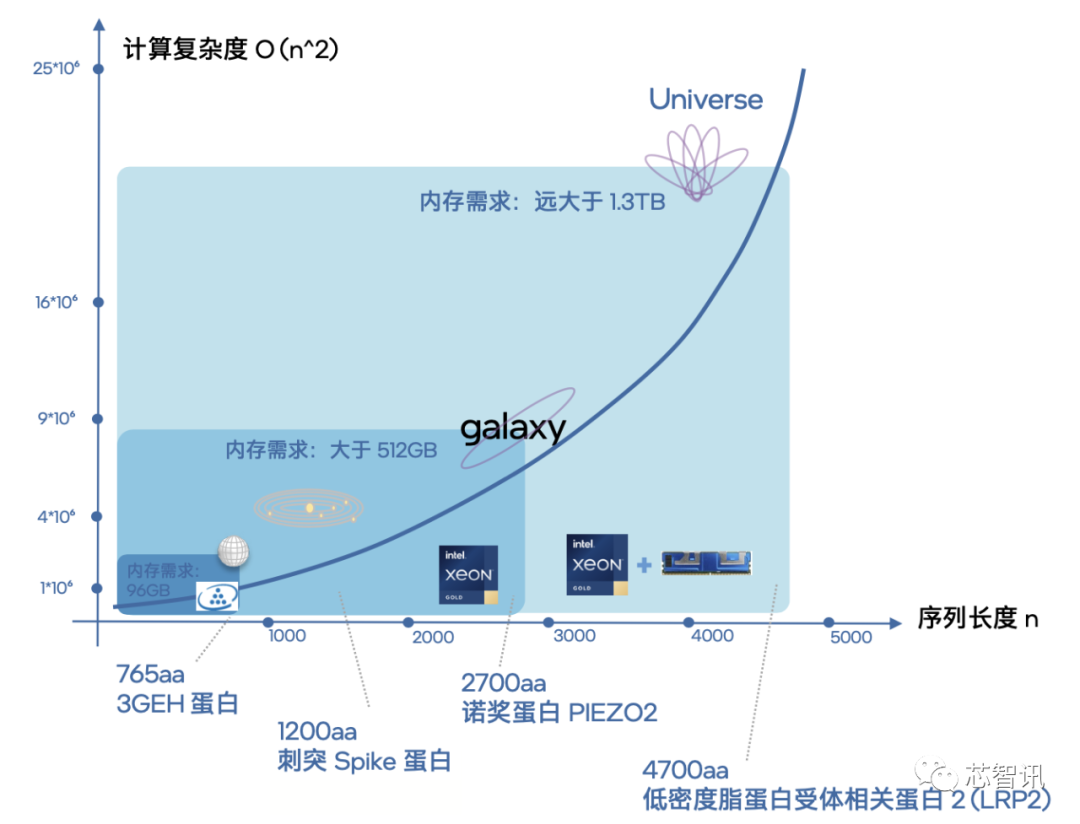
可以看到,當(dāng)?shù)鞍踪|(zhì)序列長(zhǎng)度達(dá)到4700aa時(shí),此時(shí)內(nèi)存需求就已經(jīng)大于1.3TB,計(jì)算復(fù)雜度對(duì)于系統(tǒng)來(lái)說(shuō)就相當(dāng)于“探索[敏感詞]別”了。
如果再加上64個(gè)實(shí)例并行執(zhí)行,內(nèi)存容量的需求就會(huì)沖到一個(gè)令人驚嘆的量級(jí)。
那么,一個(gè)具備超大容量?jī)?nèi)存支持的平臺(tái)就顯得尤為重要。
給至強(qiáng)可擴(kuò)展處理器配上傲騰持久內(nèi)存便可滿足這一需求。

提到傲騰持久內(nèi)存,我們并不陌生。今年6月在《用CPU方案打破內(nèi)存墻?學(xué)Paypal堆傲騰擴(kuò)容量,漏查欺詐交易量可降至1/30》一文中已經(jīng)小結(jié)了它對(duì)于AI應(yīng)用的關(guān)鍵作用,即提供更大容量的內(nèi)存子系統(tǒng)來(lái)滿足那些內(nèi)存敏感型AI應(yīng)用將更多數(shù)據(jù)貼近算力的需求。
目前[敏感詞]一代的傲騰持久內(nèi)存200系列,可以在提供接近主流DRAM內(nèi)存性能的基礎(chǔ)上,實(shí)現(xiàn)每路高達(dá)4TB的容量,或者說(shuō),與DRAM內(nèi)存組合時(shí)可提供每路高達(dá)6TB的內(nèi)存總?cè)萘俊?
有了它,我們甚至能夠實(shí)現(xiàn)10000aa序列長(zhǎng)度的蛋白結(jié)構(gòu)預(yù)測(cè)。
用了它,英特爾這個(gè)方案的優(yōu)化就基本完成,模型的總體性能也可在之前優(yōu)化步驟的基礎(chǔ)上再次得到4.56倍的提升。
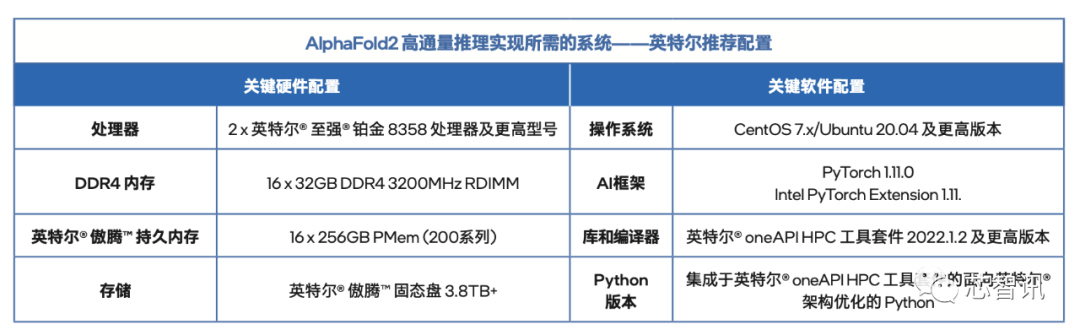
最后,附上一份用于這個(gè)優(yōu)化方案的英特爾官方推薦配置。
如果你想看更多細(xì)節(jié)中的細(xì)節(jié),也可以訪問(wèn)英特爾公開(kāi)分享的白皮書(shū)《通量提升達(dá)23.11倍!至強(qiáng)可擴(kuò)展平臺(tái)助力AlphaFold2端到端優(yōu)化》。
或者觀看英特爾聯(lián)合國(guó)際學(xué)術(shù)期刊《Science》推出的“架構(gòu)師成長(zhǎng)計(jì)劃”第二季第八期課程《AI驅(qū)動(dòng)的生命科學(xué)創(chuàng)新范式之變》。
其中不但有量子位總編輯李根、晶泰科技首席研發(fā)科學(xué)家楊明俊博士和英特爾人工智能架構(gòu)師楊威博士圍繞這個(gè)主題的精彩討論,還有晶泰科技在AI制藥領(lǐng)域的領(lǐng)先實(shí)踐分享,以及英特爾這個(gè)AlphaFold2優(yōu)化方案更為細(xì)致且可視化的呈現(xiàn)。
光說(shuō)不練假把式,英特爾這個(gè)方案看起來(lái)很美,但要真正實(shí)現(xiàn)落地才能讓人信服。
事實(shí)上,在對(duì)這個(gè)方案進(jìn)行摸索和開(kāi)發(fā)的過(guò)程中,英特爾與相關(guān)領(lǐng)域合作伙伴或用戶的協(xié)作與交流就一直沒(méi)停過(guò),不但吸收了各方的經(jīng)驗(yàn),實(shí)現(xiàn)了博采眾長(zhǎng)和互相借鑒、啟發(fā)。
在成型后,也[敏感詞]時(shí)間廣泛分享給到伙伴和用戶們,讓他們能夠根據(jù)自身特定的環(huán)境、應(yīng)用狀況和需求,開(kāi)展實(shí)戰(zhàn)驗(yàn)證和推進(jìn)更進(jìn)一步的探索。
例如國(guó)內(nèi)某高校就曾嘗試在數(shù)百臺(tái)基于至強(qiáng)可擴(kuò)展處理器的服務(wù)器上,采用該方案提供的經(jīng)驗(yàn)和方法來(lái)進(jìn)行測(cè)試,并取得了一舉兩得的結(jié)果——
其順利實(shí)踐了短序列高通量的、面向蛋白質(zhì)組學(xué)級(jí)別的批量化結(jié)構(gòu)預(yù)測(cè),既降低了蛋白質(zhì)組的AlphaFold2預(yù)測(cè)成本,又提高了集群推理的總通量。
上文提及的國(guó)內(nèi)明星AI制藥公司晶泰科技,也在自身的研發(fā)中,將自主研發(fā)的AI算法與AlphaFold2結(jié)合,從而驗(yàn)證靶點(diǎn)、精確解析活性構(gòu)象,為后續(xù)的藥物發(fā)現(xiàn)打下良好基礎(chǔ)。
通過(guò)充分利用CPU的TB級(jí)內(nèi)存支持,在公有云上部署英特爾版AlphaFold2優(yōu)化方案后,科學(xué)家可以實(shí)現(xiàn)針對(duì)短序列的單節(jié)點(diǎn)高通量推理優(yōu)化,從而加快蛋白組學(xué)結(jié)構(gòu)分析進(jìn)程,并預(yù)測(cè)序列長(zhǎng)度超過(guò)4700aa的蛋白質(zhì)序列。
這不光能拓展AlphaFold2在研發(fā)中的探索范圍,也能以更低的成本,讓更高精度的算法工具作用于更早的研發(fā)環(huán)節(jié),進(jìn)一步加速藥物發(fā)現(xiàn)。

不久前,引爆了AI for Science的AlphaFold2又公開(kāi)了新進(jìn)展——
它已經(jīng)成功預(yù)測(cè)出包括植物、細(xì)菌、真菌在內(nèi)的100萬(wàn)個(gè)物種的2.14億個(gè)蛋白質(zhì)結(jié)構(gòu),并將數(shù)據(jù)集對(duì)外開(kāi)源。
而這些,都還只是AI for Science的序幕。
在蛋白質(zhì)結(jié)構(gòu)預(yù)測(cè)、生物計(jì)算、藥物開(kāi)發(fā)之外,AI在物理、天文、化學(xué)等領(lǐng)域也開(kāi)始逐漸展露頭角。
前沿領(lǐng)域,今年《Nature》上的一項(xiàng)“改寫(xiě)物理教科書(shū)”的研究,正是通過(guò)AI開(kāi)展的。
歐洲核子研究組織(CERN)的科學(xué)家利用機(jī)器學(xué)習(xí),發(fā)現(xiàn)了質(zhì)子內(nèi)部存在5個(gè)夸克的有力證據(jù),這一成果顛覆了一直以來(lái)質(zhì)子只有三個(gè)夸克的理論。
應(yīng)用落地層面,前面提到的晶泰科技已經(jīng)構(gòu)建了一套智能計(jì)算、自動(dòng)化實(shí)驗(yàn)、專(zhuān)家經(jīng)驗(yàn)結(jié)合的三位一體的研發(fā)模式,提供一站式小分子藥物發(fā)現(xiàn)、大分子藥物發(fā)現(xiàn),藥物固體形態(tài)研發(fā),以及化學(xué)合成服務(wù)。
晶泰科技目前已建成數(shù)千平的自動(dòng)化實(shí)驗(yàn)室,與智能算法“干濕結(jié)合”,形成實(shí)驗(yàn)數(shù)據(jù)與算法預(yù)測(cè)間的交互閉環(huán),保證AI算法的產(chǎn)業(yè)落地和交付能力。

當(dāng)下行業(yè)的大勢(shì)所趨,就是利用AI,從生產(chǎn)工具、生產(chǎn)關(guān)系等不同維度突破科學(xué)探索瓶頸。
英特爾所提出的CPU版AlphaFold2加速方案在生命科學(xué)領(lǐng)域中發(fā)揮出的巨大價(jià)值就是最有力的佐證。
而這或許還只是其技術(shù)在AI for Science領(lǐng)域釋出的一個(gè)起點(diǎn)。
實(shí)際上,當(dāng)AI成為科學(xué)家的工具后,一種科研新范式已在應(yīng)運(yùn)而生。
它不同于亞里士多德時(shí)代的演繹法,不是基于經(jīng)驗(yàn)的試錯(cuò),不是將探索發(fā)現(xiàn)寄托在偶然的正確之上。
它也不是牛頓愛(ài)因斯坦時(shí)代的“假設(shè)再驗(yàn)證”,不再依賴于人類(lèi)群體中極少數(shù)天才的靈光一現(xiàn)。
它將探索未知的基礎(chǔ),[敏感詞]次不再純粹基于人類(lèi)群體的認(rèn)知。
當(dāng)海量客觀存在的數(shù)據(jù)成為“初始反應(yīng)物”,在以深度學(xué)習(xí)為代表的技術(shù)驅(qū)動(dòng)下,科研探索的邊界或許將發(fā)生前所未有的改變。
當(dāng)下AlphaFold2一系列成果震驚世人,便是對(duì)此的[敏感詞]詮釋。
接下來(lái),我們可能會(huì)看到生物、醫(yī)藥領(lǐng)域之外的更多科學(xué)家,樂(lè)意將AI作為科研探索的生產(chǎn)力、助手,更多突破人類(lèi)想象的科研成果將會(huì)涌現(xiàn)……
光是想想就非常期待了~
免責(zé)聲明:本文采摘自“芯智訊”,本文僅代表作者個(gè)人觀點(diǎn),不代表薩科微及行業(yè)觀點(diǎn),只為轉(zhuǎn)載與分享,支持保護(hù)知識(shí)產(chǎn)權(quán),轉(zhuǎn)載請(qǐng)注明原出處及作者,如有侵權(quán)請(qǐng)聯(lián)系我們刪除。
友情鏈接:站點(diǎn)地圖 薩科微官方微博 立創(chuàng)商城-薩科微專(zhuān)賣(mài) 金航標(biāo)官網(wǎng) 金航標(biāo)英文站
Copyright ?2015-2024 深圳薩科微半導(dǎo)體有限公司 版權(quán)所有 粵ICP備20017602號(hào)
