









服務熱線
0755-83044319

發布時間:2022-10-12作者來源:薩科微瀏覽:2272
制程微縮帶來的收益遞減,再加上普遍的連通性和數據的指數級增長,行業正在推動芯片設計方式、預期功能以及完成速度的廣泛變化。
過去,性能、功率和成本之間的權衡主要由大型 OEM 在行業范圍的擴展路線圖范圍內定義。芯片制造商設計芯片以滿足這些 OEM 提出的狹窄規格。但隨著摩爾定律的放緩,以及隨著越來越多的傳感器和電子設備在各處生成更多數據,設計目標和實現這些目標的手段正在發生變化。一些[敏感詞]的系統公司已經在內部進行芯片設計,以專注于特定的數據類型和用例。與此同時,傳統芯片制造商正在創建靈活的架構,這些架構可以重復使用并輕松修改以用于更廣泛的應用。
在這種新的設計方案中,需要處理數據的速度和結果的準確性可能會有很大差異。根據具體情況——例如,它是否將用于安全或任務關鍵型應用,或者它是否靠近可能產生熱量或噪音的其他組件——架構師可以權衡原始性能、每瓦性能和總擁有成本,包括可靠性和安全性。這反過來又決定了封裝的類型、內存、布局以及需要多少冗余。它還增加了新的關注點,例如跨系統的時鐘同步、封裝中組件的不同老化率,以及由于行業對各個部分如何組合在一起以及可能出現的問題的了解不足而產生的未知數。
隨著這些設計的推出,出現了一些用于定制的創新方法,以及一些一致的主題。
在最近的 Hot Chips 34 大會上,NVIDIA 高級首席工程師 Jack Choquette 預覽了該公司新的 800 億晶體管 GPU 芯片。新架構考慮了空間局部性,允許來自不同位置的數據由可用的處理元素處理,以及時間局部性,其中多個內核可以對數據進行操作。目標是允許更多的塊對數據片段進行同步或異步操作,以提高效率和速度。這與現有方法形成對比,在現有方法中,所有線程都必須等待其他數據在處理開始之前到達。
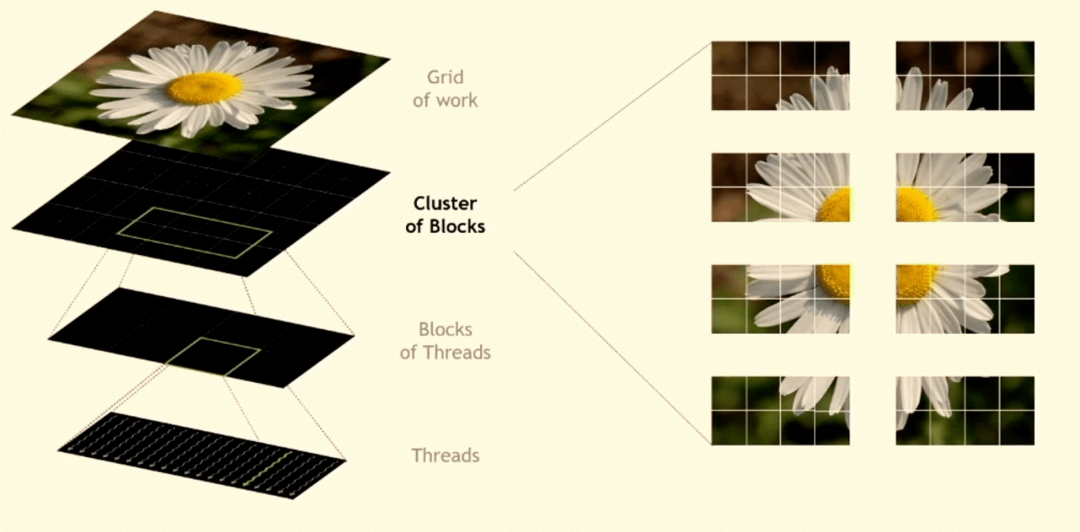
圖 1:線程塊集群,允許在相鄰的多處理器上共同調度一些處理。資料來源:NVIDIA/Hot Chips 34
AMD 高級研究員 Alan Smith 在會議上同樣介紹了“workload-optimized compute architecture”。在 AMD 的設計中,為數據轉發和重用加寬了數據路徑。與 NVIDIA 的架構一樣,其目標是消除數據路徑的瓶頸、簡化操作并提高各種計算元素的利用率。為了提高性能,AMD 不再需要不斷復制來備份內存,從而顯著減少了數據移動。
AMD 的新 Instinct 芯片包括一個靈活的高速 I/O 和一個連接各種計算元件的 2.5D elevated bridge。High-speed bridges則由英特爾首次通過其嵌入式多芯片互連橋接器 (EMIB) 商業化推出,用于使兩個或多個芯片充當一個芯片。Apple 使用了這種方法,橋接了兩個基于 Arm 的 M1 SoC 來創建其 M1 Ultra 芯片。
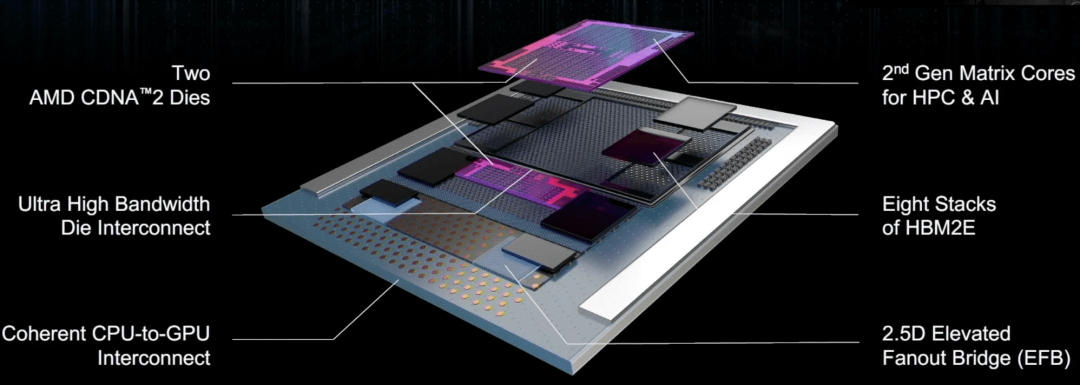
圖 2:AMD 的帶有扇出橋的多芯片方法。
資料來源:AMD/熱芯片
所有這些架構都比以前的版本更靈活,chiplet/tile 方法為大型芯片制造商提供了一種定制芯片的方式,同時仍為廣泛的客戶群提供服務。與此同時,谷歌、Meta 和阿里巴巴等系統公司更進一步,從頭開始設計芯片,專門針對其數據類型和處理目標進行調整。
特斯拉的數據中心芯片架構就是一個很好的例子。“在人工智能革命的早期階段,計算需求大致符合摩爾定律,”特斯拉低壓和硅工程副總裁Peter Bannon在最近的臺積電技術研討會上發表演講時說。“但在過去五年中,軌跡發生了明顯變化,計算需求每三四個月翻一番,因為人們已經弄清楚如何訓練越來越大的模型,從而繼續提供越來越好的結果。”
Peter Bannon說,特斯拉設計團隊設定了擴大規模的目標,“對機器的尺寸沒有實際限制”。“當時的想法是,‘如果機器對于特定型號來說不夠大,我們就會把機器做大。’ 我們希望能夠利用多個級別的并行性——訓練級別的數據和模型級別的并行性,以及訓練卷積和矩陣乘法時正在執行的固有操作中的并行性。我們希望它是一個完全可編程且靈活的硬件。”
不同之處
ASIC 一直是定制的,但在每個新的工藝節點,成本都在上升,以至于只有智能手機或 PC 等[敏感詞]量的應用程序才足以收回設計和制造成本。越來越多的系統公司通過使用他們內部設計的芯片來吸收不斷上漲的成本,并且他們希望將這些定制架構擴展到更長的時間。
為了從這些設計中榨取更高的每瓦性能,他們還在針對特定軟件功能優化芯片,以及軟件如何利用硬件——這是一個復雜且經常迭代的過程,需要通過定期軟件更新進行持續微調。例如,在數據中心的情況下,這些芯片可以提高每瓦性能并降低運行溫度,從而降低服務器機架供電和冷卻的電力成本。
還有其他考慮因素。其中:預計更多設備將作為多芯片或多設備系統的一部分,通常包括 AI/ML 的元素。
為了節省功耗和成本,設計團隊根據應用優先考慮不同的功能,然后根據特定的設計目標將多個芯片封裝在一起或劃分單個 SoC。
隨著越來越多的芯片制造商采用小芯片方法,他們需要考慮混合使用關鍵和非關鍵數據路徑。這涉及從噪聲考慮到封裝中的芯片移位、由于這些封裝中不同材料導致的熱膨脹系數以及組件本身的工藝變化等方方面面。盡管 Arm、Synopsys(ARC 處理器)等公司以及越來越多的一些 RISC-V 供應商對他們的 IP 進行了徹底的工作,但[敏感詞]案例和潛在交互的數量正在增加。
所有這些都使設計、驗證和調試過程變得更加困難,并且如果數量和對異常可能出現的位置的了解不足,就會在制造中產生問題。這就解釋了為什么越來越多的 EDA、IP、測試/分析和安全公司開始提供服務來補充內部設計團隊的工作。
瑞薩電子執行副總裁 Sailesh Chittipeddi 表示:“不再需要設計一個 CPU 來為每個工作負載執行 x、y 和 z 函數,而無需考慮開銷。”“這就是為什么所有這些公司現在都變得更加垂直化。他們正在推動他們需要的解決方案。這包括系統級別的人工智能。它包括電氣和機械特性之間的相互作用,直至您放置特定連接器的位置。它還推動更多 CAD 公司涉足系統級支持和系統級設計。”
這種轉變正在越來越多的垂直市場中發生,從手機和汽車到工業應用,隨著芯片制造商希望將其硬件定位于廣泛的新市場,它正在推動一波遠低于雷達的小型收購浪潮。例如,瑞薩在 6 月收購 Reality Analytics 的目的是為各種工業細分市場創建 AI 模型。
“這項技術可用于觀察系統中的振動并預測特定部件何時會發生故障,”Chittipeddi 說。“例如,如果你看看采礦業,如果鉆頭斷裂,可能會導致嚴重的問題。我們可以將這些模型導入我們的 MCU,用于控制這些系統。”
誰做什么
然而,特定領域的解決方案加大了 EDA 公司的壓力,要求他們找出可以自動化的共性。使用在單個工藝節點開發的平面芯片要容易得多。但隨著越來越多的市場實現數字化——無論是汽車、工業、[敏感詞]/航空、商業還是消費者——他們的目標正變得越來越不同。
隨著在不同工藝節點開發的小芯片是為定制封裝開發的,這種差異預計只會增加,定制封裝可能基于從扇出支柱到完整 3D-IC 實現的所有內容。在某些情況下,甚至可能有 2.5D 和 3D-IC 的組合,西門子 EDA 已將其標記為 5.5D。
對于 EDA 和 IP 公司來說,好消息是這顯著增加了對仿真、仿真、原型設計和建模的需求。大型系統供應商也一直在向 EDA 供應商施壓,以使更多系統公司的設計流程自動化,但沒有足夠的數量來保證這種投資。取而代之的是,系統公司已經與 EDA 和 IP 公司聯系以提供專家服務,從交易關系轉變為更深入的合作伙伴關系,并讓 EDA 公司更深入地了解各種工具的使用方式以及在哪里使用可以孕育新機會的漏洞。
是德科技副總裁兼設計與仿真部總經理 Niels Faché 表示:“許多新參與者的垂直整合程度更高,因此他們在內部做的更多。”“人們對系統級仿真的興趣要大得多,而且公司內部和公司之間對協作工作流的需求也在不斷增長。我們還看到更多的設計迭代。所以你有一個開發團隊,一個質量團隊,并且你不斷地更新設計。”
對于為 OEM 設計芯片的芯片公司來說,這只是挑戰的一部分。“如果你看一下汽車市場,就會發現設計芯片組已經不再是按要求設計了,”Faché 說。“在初始階段,芯片公司可能會使用該軟件構建參考設計,并根據其使用方式進行設置。然后,OEM 將尋求優化。這樣做是將合作推向傳統的食物鏈。例如,如果您正在開發雷達芯片,那么它不僅僅是一個雷達子系統。它是更大技術堆棧背景下的雷達。”
該堆棧可能包括射頻封裝、天線和接收器,而 OEM 使用 EDA 構建無線電。
特定應用與通用
設計團隊面臨的一個巨大挑戰是更多的設計變得前置。不僅僅是創建芯片架構,然后在設計過程中解決細節,更多的問題需要在架構級別解決。
Siemens Digital Industries Software執行副總裁 Joe Sawicki 表示:“曾經有一次芯片公司出貨的芯片耗電量過多,而 OEM 對此并不滿意。”“但你不會知道僅僅運行應用程序。人工智能使這個問題變得更大,因為它不僅僅是軟件的問題。現在,您可以在其上運行所有這些推理。如果您不關心延遲,您可以在云中放置一個通用芯片,您只需與云通信并取回數據即可。但是,如果你有實時的東西,它需要立即響應,你就無法承受這種延遲并且你想要低功耗。所以,至少對于加速器,你想要定制設計。”
Synopsys的產品營銷經理 Gordon Cooper表示同意。“如果你在使用人工智能,是 100% 的時間都在使用它,還是很高興擁有它?如果我只想說我的芯片上有人工智能,也許我只需要使用 DSP 來做人工智能,”他說。“有一個權衡,這取決于上下文。如果你想要 100% 的時間完全成熟的 AI,也許你需要添加外部 IP 或額外的 IP。”
人工智能面臨的一大挑戰是讓設備保持[敏感詞]狀態,因為算法會不斷更新。如果設計是一次性的并且所有內容都針對一種或多種算法進行了優化,這將變得更加困難。因此,雖然架構需要在性能方面具有可擴展性,但它們也需要隨著時間的推移以及系統中其他組件的上下文而具有可擴展性。
軟件更新會對時鐘造成嚴重破壞。Movellus首席執行官 Mo Faisal在 2022 年人工智能硬件峰會上的一次演講中表示:“你對芯片同步質量所做的任何事情都會影響延遲、性能、功耗和上市時間。”越來越大的芯片 - 標線大小的芯片 - 您可以優化內核并確保它與軟件很好地配合。這是矩陣乘法、圖形計算,你并行投入的核心越多越好。然而,這些芯片現在正面臨挑戰。以前,這對英特爾和 AMD 的一兩個團隊來說是個問題,現在這是每個人的問題。”
保持一切同步正在成為一個過程,而不是一個單一的功能。“你可能有不同的工作量,”Faisal說。“因此,您可能只想為一個工作負載使用 50 個內核,而對于下一個工作負載,您希望使用 500 個內核。但是當你打開接下來的 500 個內核時,你最終會給電網施加壓力并導致下降。”
同時開關噪聲也存在問題。在過去,其中一些問題可以通過冗余來解決。但在先進節點上,該裕量增加了將電子移動通過非常細的導線所需的時間和能量,這反過來又會產生電阻并增加熱耗散。因此,每個新節點的權衡變得更加復雜,并且包中不同組件之間的交互是相加的。
“如果你看一下 5G,這對汽車來說意味著與數據中心或消費者不同的東西,” Cadence產品營銷集團總監 Frank Schirrmeister在接受采訪時說。“它們都有不同的延遲吞吐量。人工智能/機器學習也是如此。這取決于域。然后,因為一切都是超連接的,它不僅在一個域內。所以它本質上需要同一芯片的許多變體,這就是異構集成變得有趣的地方。SoC 的整體解體派上用場了,因為您可以根據 binning 之類的內容執行不同的性能級別。但它本身不再是一種設計,因為某些規則不再適用。”
結論
整個芯片設計生態系統都在不斷變化,并且一直延伸到軟件。過去,設計團隊可以確保以高抽象級別編寫的軟件可以運行良好,并且在每個新節點的引入都會有定期的改進。但是隨著規模下降的好處以及隨后需要更快處理的數據的增加,現在每個人都必須更加努力地工作——他們必須與他們在過去的。
至少就功耗和性能而言,[敏感詞]的前進方式是使用定制或半定制架構為特定目的設計芯片。但這會產生一系列問題,而這些問題需要時間來解決。用于 2.5D 和 3D 設計的工具剛剛開始推出,芯片制造商正在整理計劃,以使它們變得非常具體,或者足夠通用,以便能夠在多個設計中利用其架構。無論哪種方式,每個學科的工程師都需要開始超越他們的關注領域,轉向芯片系統和系統系統。
未來是光明的,但也更具挑戰性。
免責聲明:本文轉載自“ittbank”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2024 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號
