









服務(wù)熱線
0755-83044319

發(fā)布時(shí)間:2024-06-20作者來(lái)源:薩科微瀏覽:10890
今年3月份,英偉達(dá)發(fā)布了Blackwell B200,號(hào)稱(chēng)全球最強(qiáng)的 AI 芯片。它與之前的A100、A800、H100、H800有怎樣的不同?

1.英偉達(dá)GPU架構(gòu)演進(jìn)史
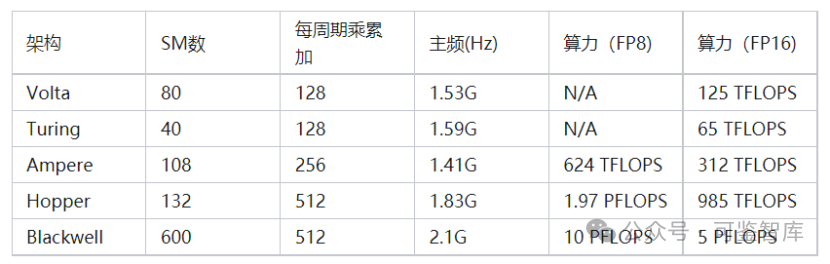
我們先回顧一下,歷代英偉達(dá)AI加速卡的算力發(fā)展史:
[敏感詞]代AI加速卡叫Volta ,是英偉達(dá)[敏感詞]次為AI運(yùn)算專(zhuān)門(mén)設(shè)計(jì)的張量運(yùn)算(Tensor Core)架構(gòu)。
第二代張量計(jì)算架構(gòu)叫圖靈(Turing),代表顯卡T4。
第三代張量運(yùn)算架構(gòu)安培(Ampere),終于來(lái)到我們比較熟悉的A100系列顯卡了。
在芯片工藝升級(jí)的加持下,單卡SM翻倍到了108個(gè),SM內(nèi)的核心數(shù)和V100相同,但是通過(guò)計(jì)算單元電路升級(jí),核心每一個(gè)周期可以完成256個(gè)浮點(diǎn)數(shù)乘累加,是老架構(gòu)的兩倍。加入了更符合當(dāng)時(shí)深度學(xué)習(xí)需要的8位浮點(diǎn)(FP8)運(yùn)算模式,一個(gè)16位浮點(diǎn)核心可以當(dāng)作2個(gè)8位浮點(diǎn)核心計(jì)算,算力再翻倍。主頻稍有下降,為1.41GHz。因此最后,A100顯卡的算力達(dá)到了V100的近5倍,為108*8*256*1.41GHz*2 =624 TFLOPS (FP8)。

Ampere 架構(gòu)
第四代架構(gòu)Hopper,也就是英偉達(dá)去年剛發(fā)布、OpenAI大語(yǔ)言模型訓(xùn)練已經(jīng)采用、且因算力問(wèn)題被禁運(yùn)的H100系列顯卡。
該顯卡的SM數(shù)(132個(gè))相較前代并未大幅提升,但是因?yàn)槿碌腡ensor Core架構(gòu)和異步內(nèi)存設(shè)計(jì),單個(gè)SM核心一個(gè)周期可以完成的FP16乘累加數(shù)再翻一倍,達(dá)到512次。主頻稍微提高到1.83GHz,最終單卡算力達(dá)成驚人的1978 Tera FLOPS(FP8),也即首次來(lái)到了PFLOPS(1.97 Peta FLOPS)領(lǐng)域。

Hopper 架構(gòu)
第五代架構(gòu)Blackwell,在這個(gè)算力天梯上又取得了什么樣的進(jìn)展呢?根據(jù)公開(kāi)的數(shù)據(jù),如果采用全新的FP4數(shù)據(jù)單元,GB200在將能在推理任務(wù)中達(dá)到20 Peta FLOPS算力。將其還原回FP8,應(yīng)該也有驚人的10 PFLOPS,這相對(duì)H100提升將達(dá)到5倍左右。
公開(kāi)數(shù)據(jù)顯示,Blackwell的處理器主頻為2.1GHz。假設(shè)架構(gòu)沒(méi)有大幅更新,這意味著B(niǎo)lackwell將有600個(gè)SM,是H100的接近4倍。Blackwell有兩個(gè)Die,那么單Die顯卡的SM數(shù)也達(dá)到了H100的2倍。
可以說(shuō),每一代架構(gòu)的升級(jí),單個(gè)GPU算力實(shí)現(xiàn)數(shù)倍增長(zhǎng)。這里,我們將從Volta架構(gòu)至今的算力天梯進(jìn)展圖列表如下,方便大家查閱:
2. A100 VS A800,H100 VS H800
為什么有A100還要A800呢?先說(shuō)說(shuō)背景
2022年10月,美國(guó)出臺(tái)了對(duì)華半導(dǎo)體出口限制新規(guī),其中就包括了對(duì)于高性能計(jì)算芯片對(duì)中國(guó)大陸的出口限制。并且以NVIDIA的A100芯片的性能指標(biāo)作為限制標(biāo)準(zhǔn);即同時(shí)滿(mǎn)足以下兩個(gè)條件的即為受管制的高性能計(jì)算芯片:
(1)芯片的I/O帶寬傳輸速率大于或等于600 Gbyte/s;
(2)“數(shù)字處理單元 原始計(jì)算單元”每次操作的比特長(zhǎng)度乘以TOPS 計(jì)算出的的算力之和大于或等于4800TOPS。
這也使得NVIDIA A100/H100系列、AMD MI200/300系列AI芯片無(wú)法對(duì)華出口。
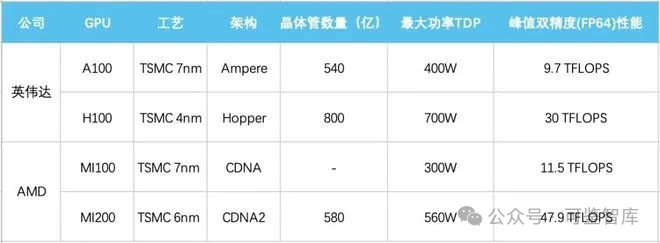
為了在遵守美國(guó)限制規(guī)則的前提下,同時(shí)滿(mǎn)足中國(guó)客戶(hù)的需求,英偉達(dá)推出A100的替代產(chǎn)品A800。從官方公布的參數(shù)來(lái)看,A800主要是將NVLink的傳輸速率由A100的600GB/s降至了400GB/s,其他參數(shù)與A100基本一致。
2023年,英偉達(dá)發(fā)布了新一代基于4nm工藝,擁有800億個(gè)晶體管、18432個(gè)核心的H100 GPU。同樣,NVIDIA也推出了針對(duì)中國(guó)市場(chǎng)的特供版H800。
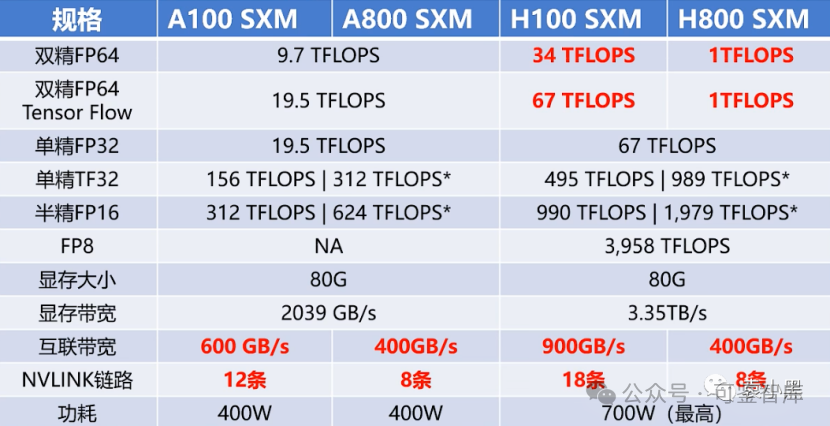
實(shí)際上,A800在互聯(lián)帶寬,即 N 維鏈和鏈路部分做了調(diào)整,從 A100的600G/s 降到了400G/s。但是在其他方面,如雙精、單精、半精等在 AI 算力方面并沒(méi)有變化。
相對(duì)而言,H800則做了較大的調(diào)整。它不僅在鏈路方面進(jìn)行了調(diào)整,保持了 8條的 NVlink,雙向互聯(lián)帶寬仍為400G,并且對(duì)雙精度算力進(jìn)行了幾乎歸零的處理。這對(duì) HPC 領(lǐng)域來(lái)說(shuō)非常關(guān)鍵,因?yàn)?FP64的雙精度算力直接減少到了一,也就是說(shuō)幾乎不讓你使用了。
接下來(lái),我們來(lái)看一下閹割后對(duì)哪些業(yè)務(wù)有很大的影響。
大模型戰(zhàn)場(chǎng): A800閹割后降低了大模型的訓(xùn)練的效率, A800 SXMM 主要是 GPU 卡之間的數(shù)據(jù)傳輸效率降低,帶寬降低 33%。以 GPT-3 為例, 規(guī)模達(dá)到 1750 億, 需要多張 GPU 組合訓(xùn)練, 如果帶寬不足則使性能下降約 4 成 (出現(xiàn) GPU 算力高需要等待數(shù)據(jù)的情況), 考慮到 A 800 和 H 800 性?xún)r(jià)比, 國(guó)內(nèi)用戶(hù)還是傾向于 A 800。由于閹割后的 A800和 H800在訓(xùn)練效率上有所下降,因?yàn)樗麄冃枰诳ㄖg交互訓(xùn)練過(guò)程中的一些數(shù)據(jù),所以他們的傳輸速率的降低導(dǎo)致了他們的效率的降低。
HPC 領(lǐng)域: A800 和 A100 在雙精方面算力一致, 所以在高性能科學(xué)計(jì)算領(lǐng)域沒(méi)有影響, 但是可惡的是 H800 直接將雙精算力直接降到了 1 TFLOPS, 直接不讓用了;這對(duì)超算領(lǐng)域的影響還是很大的。
所以影響是顯而易見(jiàn)的,在 AIGC 、HPC 領(lǐng)域中,國(guó)內(nèi)的一些企業(yè)可能會(huì)被國(guó)外的企業(yè)拉開(kāi)一定的差距。這是可預(yù)見(jiàn)到的,所以說(shuō)在一些情況下,如果我們要計(jì)算能力要達(dá)到一定的性能,它的投入可能會(huì)更高。此外,我們只能從國(guó)外借殼,通過(guò)成立分公司的方式,把大模型訓(xùn)練的任務(wù)放在國(guó)外,我們只是把訓(xùn)練好的成果放在國(guó)內(nèi)去用就可以了。但是,這只是一種臨時(shí)性的方案,特別是面臨數(shù)據(jù)出境風(fēng)險(xiǎn)。
3.后話(huà)
眾所周知,目前美國(guó)對(duì)中國(guó)的芯片限制越來(lái)越嚴(yán)格,在GPU上面也是如此。
2022年美國(guó)禁掉了高性能GPU芯片,包括A100、H100等,而2023年又禁掉了A800、H800、L40、L40S,甚至連桌面端顯卡RTX 4090都禁了。
因此,國(guó)內(nèi)科技企業(yè)也積極調(diào)整產(chǎn)業(yè)策略,為未來(lái)減少使用英偉達(dá)芯片做準(zhǔn)備,從而避免不斷調(diào)整技術(shù)以適應(yīng)新芯片的巨大代價(jià)。阿里和騰訊等云廠商將一些先進(jìn)的半導(dǎo)體訂單轉(zhuǎn)移給華為等本土公司,并更多地依賴(lài)其內(nèi)部開(kāi)發(fā)的芯片,百度和字節(jié)跳動(dòng)等企業(yè)也采取了類(lèi)似措施。顯然,國(guó)內(nèi)企業(yè)選擇“英偉達(dá)+自研+國(guó)產(chǎn)芯片”三管齊下進(jìn)行探路。
免責(zé)聲明:本文采摘自網(wǎng)絡(luò),本文僅代表作者個(gè)人觀點(diǎn),不代表薩科微及行業(yè)觀點(diǎn),只為轉(zhuǎn)載與分享,支持保護(hù)知識(shí)產(chǎn)權(quán),轉(zhuǎn)載請(qǐng)注明原出處及作者,如有侵權(quán)請(qǐng)聯(lián)系我們刪除。
友情鏈接:站點(diǎn)地圖 薩科微官方微博 立創(chuàng)商城-薩科微專(zhuān)賣(mài) 金航標(biāo)官網(wǎng) 金航標(biāo)英文站
Copyright ?2015-2024 深圳薩科微半導(dǎo)體有限公司 版權(quán)所有 粵ICP備20017602號(hào)
